Scientific Frontiers
Beyond Scaling Laws
This research pillar develops new learning methods and architectures that move beyond the limits of today’s neural scaling laws — reaching higher performance with far less compute. Rather than scaling by brute force, it pioneers a new paradigm for foundation models: efficient, practical, and sustainable.
Read more →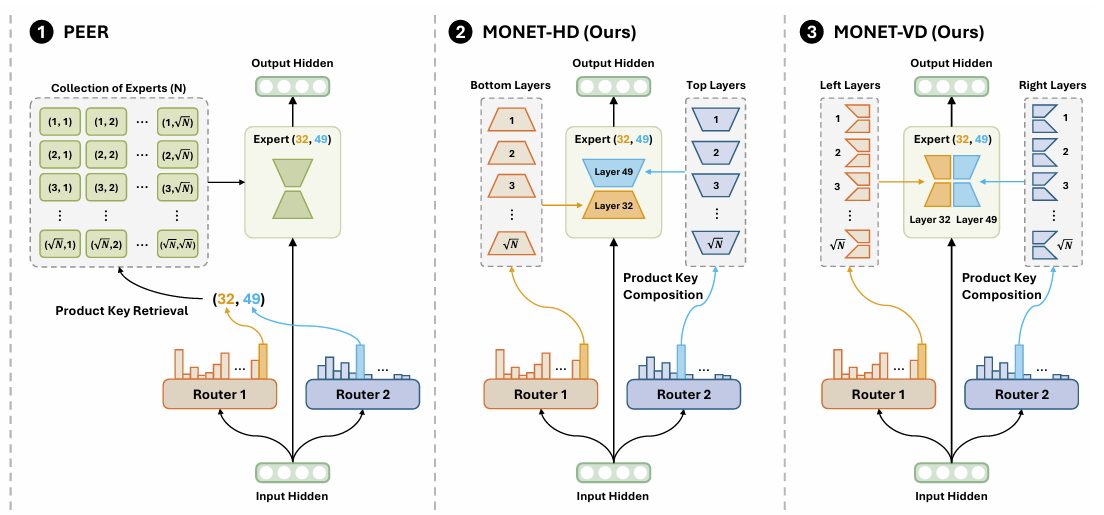
Publications List
Breakthrough in Neural Scaling Law
# Breakthrough in Neural Scaling Law